A100에 새로이 적용된 MIG 기능에 대해
NVIDIA에서 제공하는 매뉴얼은 한번 다 읽어볼 필요가 있을 것 같아 필요한 부분만 일부 정리해봤다.
NVIDIA MIG User Guide 정리
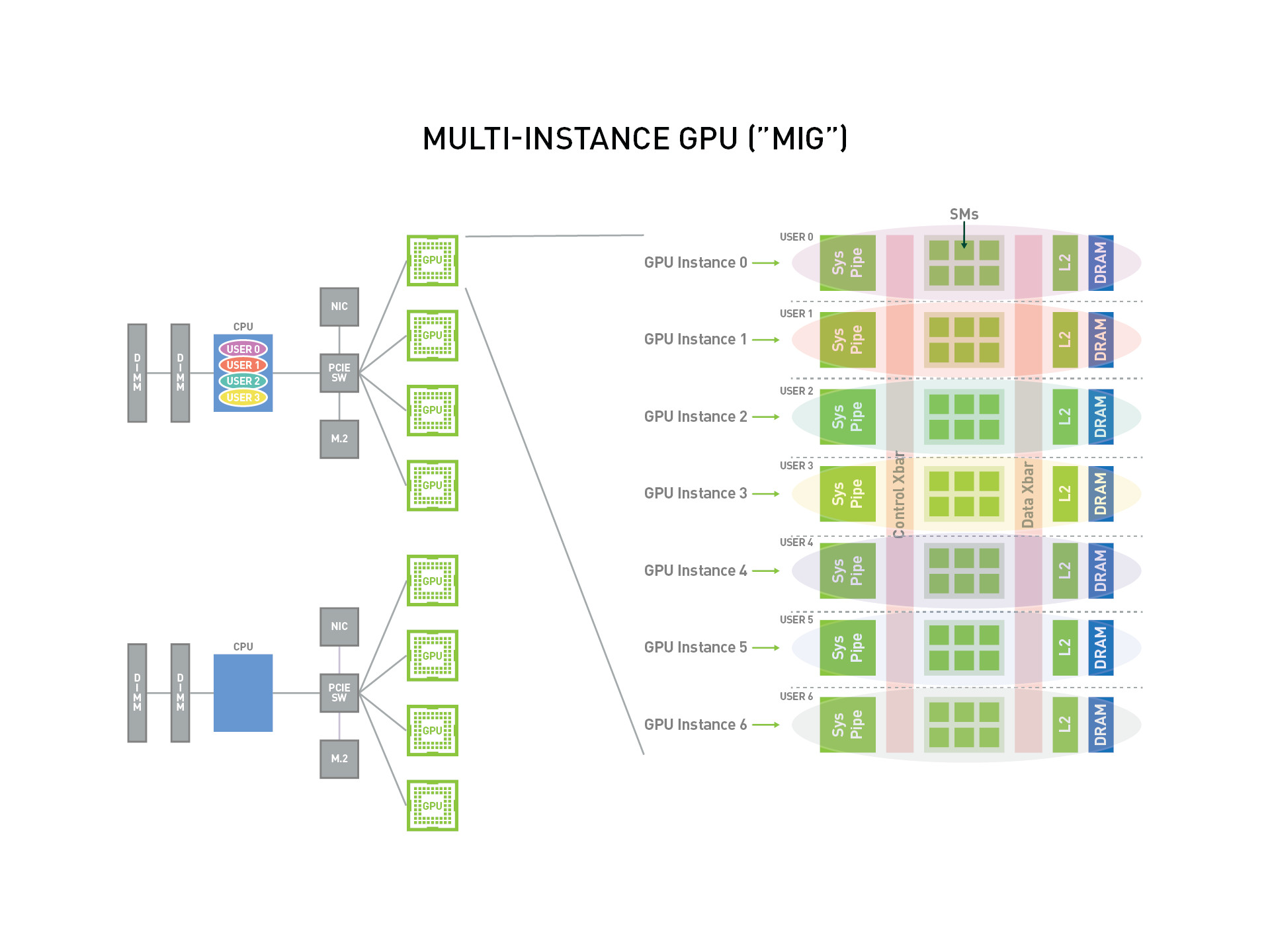
MIG는 최대 7 개의 CUDA Application을 위한 GPU 인스턴스를 다중 사용자에게 제공하여 GPU 사용률을 올리기 위한 기능이다.
다중 사용자의 Use case를 가지는 Cloud Service Provider를 위해, MIG는 사용자 간 작업 영향을 분리하는 것을 보장한다.
NVIDIA A100 GPU를 이용했을때, 사용자는 가상 GPU Instance를 실제 물리 GPU처럼 사용하여 작업을 수행할 수 있다.
MIG는 Linux operating system에서 동작하며, Docker Engine 은 지원하는데 Kubernetes 나 VM (Red Hat Virtualization and VMware vShpere) 지원은 아직으로 보인다.
1. 용어 ( Terminology )
Streaming Multiprocessor
A Streaming multiprocessor(SM) executes compute instructions on the GPU.
스트리밍 프로세서는 GPU 상에서 compute instance를 실행한다.
GPU Context
A GPU context is analogous to a CPU process. It encapsulates all the resources
necessary to execute operations on the GPU, including a distinct address space, memory
allocations, etc. A GPU context has the following properties:
‣ Fault isolation
‣ Individually scheduled
‣ Distinct address space
GPU 컨텍스트는 하나의 CPU 프로세스와 유사하다. GPU에서의 동작을 위해 필요한 자원들을 가지고 있는데, 이는 주소 공간, 메모리 할당 등을 포함한다. GPU Context는 Fault isolation, Individually scheduled, Distinct address spage 요소를 지닌다.
CPU Process에서 서로 메모리를 공유하지 않고 하나의 프로세스에서 발생하는 문제가 다른 프로세스에 영향을 주지 않는 것 처럼, GPU Context도 유사하게 받아들이면 될 것 같다.
GPU Engine
A GPU engine is what executes work on the GPU. The most commonly used engine is
the Compute/Graphics engine that executes the compute instructions. Other engines
include the copy engine (CE) that is responsible for performing DMAs, NVDEC for
video decoding, NVENC for encoding, etc. Each engine can be scheduled independently
and execute work for different GPU contexts.
GPU 엔진은 GPU에서 작업을 수행하는 주체이다. 대개 Compute/Graphics 엔진이 사용되며, 다른 Copy engines (DMAs, NVDEC 등 을 수행)도 이에 포함된다.
각 엔진은 독립적으로 스케줄하고 서로 다른 GPU context를 위한 작업을 수행한다.
GPU Memory Slice
A GPU memory slice is the smallest fraction of the A100 GPU’s memory, including the
corresponding memory controllers and cache. A GPU memory slice is roughly one
eighth of the total GPU memory resources, including both capacity and bandwidth.
GPU 메모리 슬라이스는 A100 GPU 메모리의 가장 작은 부분(분할)이다. GPU memory slice는 Capacity(용량)와 Bandwidth(대역폭)를 모두 포함한 전체 GPU 메모리의 1/8 정도이다.
GPU SM Slice
A GPU SM slice is the smallest fraction of the SMs on the A100 GPU. A GPU SM slice is
roughly one seventh of the total number of SMs available in A100 when configured in
MIG mode.
GPU SM Slice는 A100 GPU 상의 SM들의 가장 작은 부분이다. MIG mode를 사용하도록 설정했을 때 전체 가용 SM에서 1/7 정도이다.
GPU Slice
A GPU slice is the smallest fraction of the A100 GPU that combines a single GPU
memory slice and a single GPU SM slice.
GPU Slice 는 하나의 GPU memory slice와 GPU SM slice를 결합한 A100 GPU의 최소 단위 분할이다.
GPU Instance
A GPU Instance (GI) is a combination of GPU slices and GPU engines (DMAs, NVDECs,
etc.). Anything within a GPU instance always shares all the GPU memory slices and
other GPU engines, but it's SM slices can be further subdivided into compute instances
(CI). A GPU instance provides memory QoS. Each GPU slice includes dedicated GPU
memory resources which limit both the available capacity and bandwidth, and provide
memory QoS. Each GPU memory slice gets 1/8 of the total GPU memory resources and
each GPU SM slice gets 1/7 of the total number of SMs.
GPU 인스턴스(GI)는 GPU 슬라이스와 GPU 엔진(DMAs, NVDECs 등)의 조합이다.
GI 내의 모든것은 항상 모든 GPU 메모리의 슬라이스 및 기타 GPU 엔진을 공유하지만 SM 슬라이스는 Compute instance(CI)로 더 세분화될 수 있다. 하나의 GPU 인스턴스는 메모리 QoS를 제공하며, 각 GPU Slice는 사용 가능한 용량과 대역폭을 한정하는 전용 GPU 메모리 자원을 포함하고, 이 또한 메모리 QoS를 제공한다. 각 GPU memory slice는 총 GPU 메모리 리소스의 1/8을 가지며, GPU SM slice는 전체 SM 개수의 1/7을 갖는다.
Compute Instance
A GPU instance can be subdivided into multiple compute instances. A Compute
Instance (CI) contains a subset of the parent GPU instance’s SM slices and other GPU
engines (DMAs, NVDECs, etc.). The CIs share memory and engines.
GPU 인스턴스는 여러 컴퓨팅 인스턴스들로 세분화 될 수 있다. 하나의 CI는 상위 GPU 인스턴스의 SM Slice들과 다른 GPU 엔진들을 가지며, CI 들은 메모리와 엔진들을 공유한다.
2. 파티셔닝 ( Partitioning )
The number of slices that a GI can be created with is not arbitrary.
GPU Instance 가 만들 수 있는 슬라이스의 개수는 임의적이지 않다.
=> 슬라이스를 맘대로 만들어 낼 수는 없다.
NVIDIA driver API는 여러개의 "GPU Instance Profiles"를 제공하고 사용자는 이런 프로파일 중 하나를 명시함으로써 GI 들을 만들어 낼 수 있다.
GPU Profile은 제품마다 달라지며 아래 예시는 "A100-SXM4-40GB" 의 Instance profile이다.
만약 A100-SXM4-80GB 제품을 사용한다면, 프로파일 이름은 메모리 크기에 따라 1g.10gb, 2g.20gb, 3g.40gb, 4g.40gb, 7g.80gb 와 같이 달라질 것이다.
GPU Instance Profiles ( A100-SXM4-40GB )
| Profile Name | Fraction of Memory | Fraction of SMs | Hardware Units | Number of Instances Available |
| MIG 1g.5gb | 1/8 | 1/7 | 0 NVDECs | 7 |
| MIG 2g.10gb | 2/8 | 2/7 | 1 NVDECs | 3 |
| MIG 3g.20gb | 4/8 | 3/7 | 2 NVDECs | 2 |
| MIG 4g.20gb | 4/8 | 4/7 | 2 NVDECs | 1 |
| MIG 7g.40gb | Full | 7/7 | 5 NVDECs | 1 |
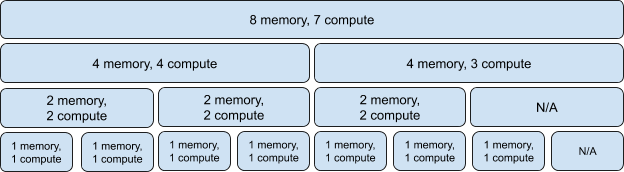
인스턴스 조합을 사용함에 있어서 예외가 하나 있는데, 이는 4 memory, 4 compute 조합 2개를 사용할 수 없는 것이다. 하지만, 4 memory, 3 compute는 사용이 가능하다. ( 4m 4c 는 MIG 4g.20gb, 4m 3c 는 MIG 3.20gb )
아래는 3개의 인스턴스를 사용하는 예시이다.
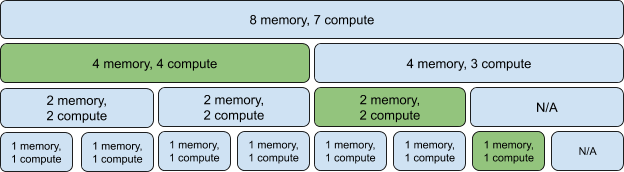
아래 두개의 GPU Instance 조합을 통해 GPU에서 생성되는 Intance의 배치를 볼 수 있다.
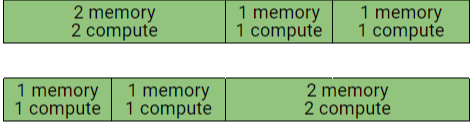
이 그림이 실제로 GPU Instance가 GPU 상에서 생성되면 물리적으로 해당 Instance 가 어디에서 존재하게 되는지를 보여주는 그림이다. 실제 하나의 GPU Instance의 물리적 위치는 다른 GPU Instance들이 초기화될 수 있도록 제 역할을 수행할 것이며, 이를 위해서 분할이 발생할 수 있다.
3. 고려사항 ( Consideration )
MIG의 기능은 CUDA 11.0 / R450 release 드라이버 부터 사용 가능하다.
System 고려사항
NVIDIA A100을 MIG Mode로 사용시 아래와 같은 부분을 고려할 필요가 있다.
- MIG는 CUDA 11/R450이 적용 된 Linux OS에서만 동작한다. NVIDIA DatacenterLinux driver 450.80.02 or higher 를 권장한다. 이는 cuda-drivers-450 패키지를 통해 인스톨 가능하다.
- 지원 가능한 구성들은 다음과 같다:
- Bare-metal
- GPU pass-through to Linux guests on top of supported hypervisors
- vGPU on top of supported hypervisors.
MIG는 단일 A100상에서 vGPU의 병렬 수행을 허용한다. (vGPU가 자원 간의 Isolation을 보장하는 경우)
A100 제품에서 MIG mode를 설정하는 것은 super-user 권한이 필요하며, GPU reset이 필요하다. MIG mode로 설정한 뒤 instance 의 관리는 dynamic 하게 사용 가능하다. MIG mode의 설정은 per-GPU 기반이다.
이와 유사하게 ECC mode에서는 MIG mode 설정은 항상 reboot이필요하다.
MIG 설정을 위해서는 driver module상에서 handle을 가지는 모든 데몬은 종료해야 하며, 이는 각종 GPU 모니터링에 사용되는 DCGM 이나 nvsm 등을 종료해야 함을 의미한다.
MIG mode를 Toggling 하기 위해서는 CAP_SYS_ADMIN 용량이 필요하다. 인스턴스 생성/삭제 같은 MIG 관리 작업은 기본적으로 superuser에게 허용되지만, /proc/ 에 있는 MIG capabilities의 권한관리를 통해 인가되지 않은 사용자에게도 이 권한을 위임할 수 있다.
4. MIG 장치 이름 ( MIG Device Name )
기본적으로, MIG 의 Device 이름은 단일 "GPU Instance" 그리고 단일 "Compute Instance"로 구성되어 있다.
전체 메모리와 GPU Instance의 compute slice 갯수에 따른 MIG device의 Naming convention이 어떻게 이루어 지는지 아래 표를 참고하면 이해할 수 있을 것이다.
전체 GI의 Capacity를 소비하는 하나의 CI가 생성되었을 때, 그 CI 의 크기가 Device name을 결정한다.
아래 설명은 A100-SXM4-40GB를 기준으로 설명한다. 위에서도 한번 언급은 되었지만 메모리가 80GB인 제품의 경우 Total memory size로 인해 1g.10gb, 2g.20gb, 3g.40gb, 4g.40gb, 7g.80gb 로 바뀐다.
Device name when using a single CI
| Memory | 20gb | 10gb | 5gb |
| GPU Instance | 3g | 2g | 1g |
| Compute Instance | 3c | 2c | 1c |
| MIG Device | 3g.20gb | 2g.10gb | 1g.5gb |
| GPCGPCGPC | GPCGPC | GPC |
각 GI는 여러개의 CI들로 세분화 될 수 있으며, 이는 사용자들의 Workloads에 따라 달라질 것이다.
아래 표는 이런 경우의 예시이며, 이 예시는 3g.20gb device를 세분화 하는 예시이다.
Device names when using multiple CIs
| Memory | 20gb | 20gb | ||||
| GPU Instance | 3g | 3g | ||||
| Compute Instance | 1c | 1c | 1c | 2c | 1c | |
| MIG Device | 1c.3g.20gb | 1c.3g.20gb | 1c.3g.20gb | 2c.3g.20gb | 1c.3g.20gb | |
| GPC | GPC | GPC | GPCGPC | GP | ||
5. 짧은요약
MIG는 최대 7개의 GPU Instance 내에서 사용자 요구에 따른 자원을 제공하는 NVIDIA A100에 도입 된 GPU feature이다. CUDA application 수행을 지원하며, 자원 간 Isolation 을 지원함으로써 Resonable 한 GPU Provisioning 을 가능하게 한다.
이러한 MIG의 기능을 통해 사용자 Workload를 최대한으로 수행할 뿐 아니라, 기존에 다중 Process가 GPU memory를 공유함으로써 발생하는 고려사항에 대한 고민을 덜어준다.
다중 Workload를 하나의 GPU에서 수행하는 것은 Data Center에서의 투자나 Cloud Computing 환경에서 효율을 극대화 할 수 있는 매력적인 기능이라 생각된다.
출처 :
- NVIDIA Multi-Instance GPU User Guide: docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html#concepts
'Working on' 카테고리의 다른 글
| [Effective C++] operator= 에서는 자기대입에 대한 처리가 빠지지 않게하자 (0) | 2021.05.19 |
|---|---|
| [Effective c++] 항목 10: 대입 연산자는 *this 참조 반환하게 하자. (0) | 2021.05.12 |
| NVIDIA NVTAGS ( Topology-Aware GPU Selection ) 메뉴얼 읽기 - 1 (0) | 2021.04.21 |
| [Effective C++] 항목 9: 객체 생성 및 소멸 과정 중에는 절대로 가상함수를 호출하지 말자 (0) | 2021.04.09 |
| Getting started with MIG (0) | 2021.03.21 |
